WM 基础
概述
世界模型是机器对外部环境的生成式模拟器,它相当于给机器添加了一个能够预测外部环境状态在未来时域内如何演变的功能。
传统的端到端基于“感知-决策-控制”架构,没有关注未来环境变化信息;VLA基于外部感知,可能会隐式地学习到未来环境的变化从而做出更加有效的动作,而 WM 显式地预测未来(无论是隐空间还是生成式 WM),因此能够借助未来信息做出更优的决策。
这种显式预测允许系统进行 “模型预测控制”或在想象中进行强化学习。这不仅能做出更优决策,还能极大提高样本效率和安全性。
WM 的作用
- 支持决策与规划
- 闭环仿真与策略评估
- 数据引擎与长尾场景生成
- 预训练与下游任务适配
WM 架构
主流两种 WM 架构,分别为 隐空间与生成式 世界模型:
- 隐空间/决策型世界模型:将高维的观测输入压缩到一个紧凑的潜在特征空间,直接在这个特征空间内对环境状态进行时间演化,而不计算未来外界的像素与视频,计算时间更低。
- 生成式/像素级世界模型:直接在高维的观测数据上运行,输出高保真、高时空一致性的未来视频帧或3D/4D场景来刻画未来环境的状态。
隐空间/决策型世界模型:
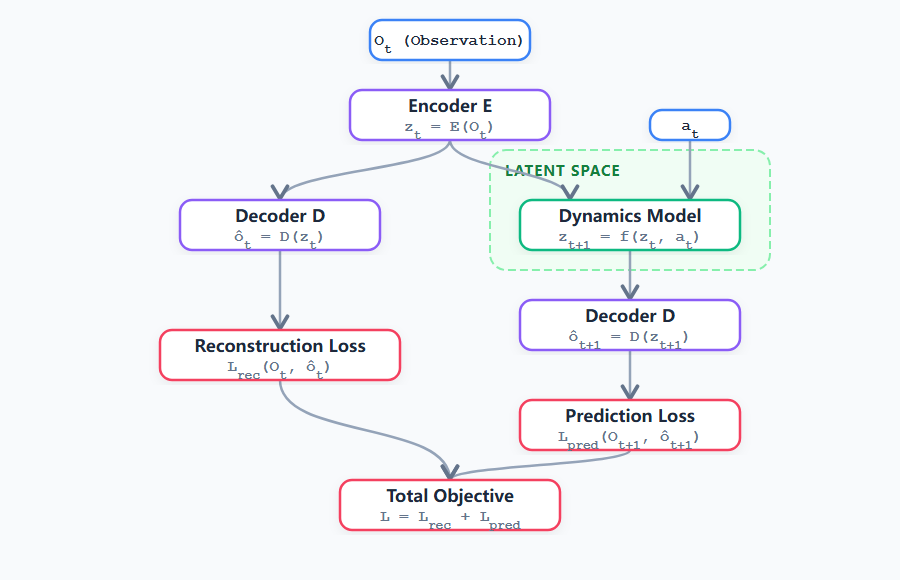
- 重构与正则化,编解码训练,一个具有编码器、动力学模型、解码器的架构,在训练时环境(图像)与自车状态进入编码器,被压缩到紧凑的潜在特征隐空间,动力学模型基于隐空间状态和动作指令预测下一步环境与自车状态的隐状态,解码器则根据隐空间状态输出重构的图像。训练时一方面优化重构图像和原始图像的对数似然,由此可以保障隐空间能够保留环境状态,另一方面还要优化动力学模型对下一时刻的隐状态量的估计能力。其流程为:
- Step 1-编码器前向传播
- Step 2-解码器重构
- Step 3-动力学模型前推
- Step 4-验证未来
- 联合嵌入预测架构,掩码训练,有一个目标编码器、上下文编码器、预测器(动力学模型);在训练时就是目标编码器输入历史当前及未来时刻的环境图像,上下文编码器则是被遮掩未来状态的;对上下文编码器输入历史及当前的环境状态,得到隐空间状态,使用动力学模型对其进行预测,然后和目标编码器计算得到的下一时刻的隐状态进行对比,优化二者的 L2距离或余弦相似度等等。 其中,为了避免模型坍塌,还会阻止目标编码器的反向传播,而是使用上下文编码器的参数缓慢更新
生成式/像素级世界模型:
- 扩散建模:通过对未来时刻的环境状态逐步添加高斯噪声,训练模型让它基于历史状态学习,实现逆向去噪。和扩散模型原理一致,不过区别于静态图像建模是输入自己,这里输入的是历史状态。训练的目标就是最小化网络预测的下一时刻的状态的噪声与真实噪声逐渐的误差(有一个问题,状态估计里面传感器的噪声不止高斯噪声,这个图像里面应该也是,还有什么彩色噪声等等,为什么只添加高斯噪声呢,会不会有不利影响)
- 自回归建模:就是和LLM,VLM相似的建模思路,把历史状态、车辆状态等等都映射到一个特征空间,然后学习,最大化在给定历史条件情况下,预测序列中下一个词元的条件概率。推理时,对这些输入数据进行tokenizer,然后以当前序列预测下一个词元。
- 自回归与扩散混合:分别处理,对离散的文本、动作指令使用自回归建模,对图像/视频帧则是使用扩散模型。说是现在前沿的方法 Transfusion、Show-o.