TransFuser
背景提要
TransFuser 是 21 年德国图宾根大学和马克斯·普朗克智能系统研究所的一个顶尖自动驾驶研究团队提出的,主要工作是使用 transformer 构建了相机与激光雷达的多模态融合框架,并最终实现了优秀的自车航点预测能力。
TransFuser 是多模态大模型开创之作。在此之前已有大量研究实现了多模态的数据融合,camera 和 Lidar 的数据融合并不是什么新鲜的创新工作,但是此前的研究多基于“几何特征投影”和“局部邻域信息聚合”的特殊处理手段,局部信息假设使其在高密度智能体的复杂城市驾驶环境中性能受限。
得益于 Transformer 强大的长距离全局上下文依赖建模能力以及跨模态特征交互能力,TransFuser 彻底突破了传统几何融合、后期融合方法仅能实现局部邻域特征聚合的局限,能精准捕捉复杂城市场景中远距离交通灯与近处动态车辆的语义关联、多智能体间的交互关系等对安全驾驶至关重要的全局信息。当然,同样离不开研究团队在跨模态融合架构方面的设计。
项目地址:https://github.com/autonomousvision/transfuser
架构
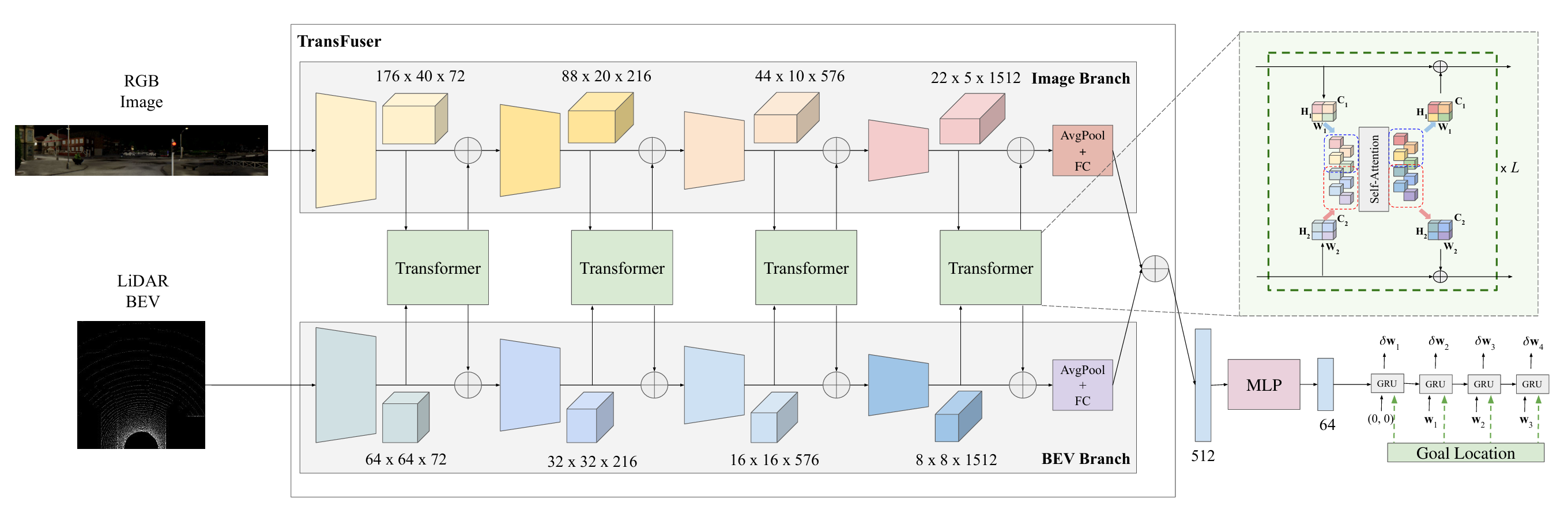
TransFuser 的架构如文章顶部的论文原图所示,论文提出的框架主要由左边的 TransFuser 多模态特征融合模块 以及 右边的以 GRU 为主体的另一个模块组成。
右边 GRU 网络的输入是经 TransFuser 融合后的输入信息、目标位置(Goal Location),输出的是预测的自车航点,论文提出的框架相当于是在做轨迹规划。
而左边的 TransFuser 模块的输入为 camera 的 RGB 图像以及 LiDAR的 BEV 视图,输出为融合后的多模态特征。
并且可以注意到,TransFuser 不是将输入特征之间变为 token 并输入到一个 transformer 中进行融合。而是并行了两条 branch,分别处理两种模特的数据,对其进行特征提取,然后仅在每次特征提取后使用 transformer 进行模态交互。自然,这里面主要有两个可学习的内容,分别是特征提取模块、模态交互模块。
TransFuser 的特征提取模块使用的是RegNetY-3.2GF(两个Branch都是,不过camera使用现成的,Lidar自己训练了)。
而 TransFuser 的模态交互模块就比较有趣。由于这部分是做模态交互,不需要自回归逻辑,所以模态交互模块仅使用了 encoder,因此内部就是多个 block,每个 block 里面是层归一化、多头自注意力、残差连接、层归一化、FFN、残差连接的形式。
输入输出就是这个模态交互的重点。其输入是将 camera 和 Lidar 的特征分别降维变为 tokens,然后拼在一起作为输入,再 embedding + 位置编码;输出时,按照输入的拼接方式将输出反向拆解为 camera 和 Lidar 的特征,再和各自的原输入特征相加,其结果作为下一个特征提取器的输入。
具体以第一层来说,原始的 camera 全景图像(704×160×3)与 LiDAR BEV 伪图像(256×256×3)首先经过 RegNetY-3.2GF 第一阶段的下采样,分别提取出尺寸为176×40×72和64×64×72的特征图;接着,为了适配 Transformer 的输入要求,这两个特征图被展平为一维token序列(Camera为7040×72,LiDAR为4096×72)并拼接成维度为11136×72的总序列,在加上同尺寸(11136×72)的位置编码后送入第一个Transformer(T1);T1在此11136×72的统一维度上完成多头自注意力计算并输出等大的融合序列,随后该序列被重新拆分回7040×72与4096×72的两部分,分别重塑回原先的空间尺度(176×40×72和64×64×72),最后与传入Transformer之前的对应初始特征图进行残差加和,作为各自支路下一阶段的输入。
主要创新点
TransFuser的核心创新点可精简为4点:
- 融合机制革新:首次将Transformer自注意力机制系统性引入端到端自动驾驶,用全局跨模态注意力替代传统局部几何投影融合,突破了复杂城市场景下长距离上下文建模的局限。
- 架构设计创新:提出多分辨率跨模态融合架构,在特征提取全流程嵌入Transformer融合,平衡了模态特征特异性与全局信息交互,同时提出纯图像基线Latent TransFuser,成为领域标准参考。
- 评估基准创新:构建了Longest6高难度基准,解决了CARLA官方排行榜评估受限、无法开展消融实验的痛点,为自动驾驶复杂场景评估提供了统一平台。
- 范式优化创新:仅用单阶段行为克隆模仿学习,就实现了CARLA榜单SOTA性能,相较传统方法降低48%的碰撞率,证明了简单IL范式结合全局融合的有效性,无需复杂多阶段训练或强化学习。
拓展
Transfuser 为什么强
TransFuser 之所以能在端到端自动驾驶领域取得远超同期方法的优异性能,核心在于它首次将 Transformer 的全局自注意力机制系统性地与多模态传感器融合深度结合,彻底突破了传统几何融合、后期融合方法仅能实现局部邻域特征聚合的固有局限,能够精准捕捉复杂城市场景中远距离交通灯与近处动态车辆的语义关联、多智能体间的交互关系等对安全驾驶至关重要的全局上下文信息。
同时它针对图像与 LiDAR 的模态互补特性做了深度定制化设计,通过多分辨率层级融合实现了浅层细节特征与深层语义特征的跨模态交互,搭配残差连接平衡了模态特异性与融合充分性,再辅以多任务辅助监督强化特征的场景表征能力、自回归航点预测框架适配驾驶轨迹的连续性需求,再加上配套构建的 Longest6 高难度基准完成了充分的场景验证与工程化优化。
最终让 Transformer 的全局建模能力在端到端自动驾驶场景中得到最大化发挥,不仅在 CARLA 官方排行榜实现了驾驶分数的大幅领先,还相较传统几何融合方法降低了 48% 的每公里碰撞率,同时提出的 Latent TransFuser 纯图像基线也成为了领域内的标准参考,兼具性能优势与架构通用性。
Transfuser 的局限
尽管 TransFuser 在端到端自动驾驶的多模态特征融合领域做出了开创性贡献,但其架构设计与学习范式仍存在若干关键局限性,制约了其在复杂真实场景中的可扩展性与鲁棒性。其核心局限性可归纳为以下四个方面:
计算复杂度与高分辨率扩展瓶颈 TransFuser 依赖的全局自注意力机制在进行中间层融合时,会引入与输入序列长度 呈平方关系的计算与空间复杂度 。这种架构特性导致模型在处理高分辨率图像或扩展至多相机环视系统时,面临严峻的显存消耗与算力瓶颈。受限于此,原始网络架构通常只能处理极低分辨率的单目前向视图,难以满足高级别自动驾驶对大视场与高精度感知的刚性需求。
时序上下文缺失与动态状态建模不足 该模型的感知主干网络仅依赖单帧传感器数据进行空间特征提取与多模态对齐。尽管在其解码阶段引入了门控循环单元用于自回归航点预测,但由于感知前端缺乏历史帧时序信息的有效累积与融合,模型无法显式提取周围交通参与者的运动学特征(如速度、加速度及运动趋势)。这导致模型在应对高动态环境或突发性障碍物时,决策输出易表现出迟滞性与不连续性。
模仿学习固有的协变量偏移与因果混淆 作为一种纯粹的端到端行为克隆模型,TransFuser 的泛化能力高度受限于专家演示数据的分布。一方面,模型易受因果混淆影响,倾向于拟合数据中的伪相关性而非真实的驾驶因果逻辑;另一方面,模型在闭环推理阶段极易遭遇协变量偏移。 当自车受环境噪声干扰而微小偏离专家数据覆盖的标称状态空间时,单步误差将随时间呈指数级累积,引发级联失效,且模型缺乏从未知状态流形中自动恢复的鲁棒性。
模态高度耦合与系统鲁棒性缺陷 其多尺度中间层融合架构对异构传感器的输入完备性具有强依赖性。RGB 与 LiDAR 分支在特征提取的各个阶段被硬编码绑定,这意味着一旦在真实部署中遭遇单一传感器信号降级或物理失效(如摄像头被恶劣天气遮挡或雷达点云缺失),残缺的模态输入将直接破坏融合特征向量的完整性。由于缺乏有效的模态解耦设计与优雅降级冗余机制,该系统在传感器故障的边缘场景下难以维持稳定的驾驶策略输出。